Zabbix Preprocessing
介绍
监控结果预处理可以用来定义和根据相应的规则来对采集到的数据进行转换,通过预处理管理进程来管理这些预处理,而具体的步骤则是由多个 work 进程来完成。
Preprocessing 页可以对接收到的数据定义转换规则,可以允许一个或多个规则同时存在,之后才将转换后的数据写入到数据库。如果有多个规则存在,则会按照定义的顺序来依次进行转换。Preprocessing 可以运行在 zabbix server 或 zabbix proxy 上。
为什么需要 Preprocessing,因为很多情况下我们获取到的数据是各种各样的格式,并不适合计算、合并或优化存储空间。
Preprocessing 支持类型
从 3.4 版本开始支持 preprocessing,原生只支持几种情况:
- 自定义倍数
- 数值型转换(布尔、hex 等)
- 简单改变(计算每秒变化等)
如果需要更复杂的转换,则需要自己通过其他工具(python、php)等来处理数据,而后来 preprocessing 也支持了更多的方法:
- 正则表达式
- 简单裁剪
- XPath 和 JSONPath 支持
随着时间推移,在 4.2 版本中逐步增加了更多的扩展
- JavaScript 和 Prometheus 支持
- Validation-用于验证数据是否符合某些规则
- Throttling-用于丢弃无用数据
- 自定义错误处理-为了更好的可读性
zabbix4.4 中同样进行了非常多的改进,带来了完全不一样的体验:
- 通过 XPath 来处理 XML 数据
- 通过 JSONPath 来抽取和分割 JSON 数据
- 扩展自定义错误处理
- CSV 转换到 JSON
- 将 WMI, JMX 和 ODBC 数据收集到 JSON 数组,然后通过 JSONPath 进行处理
监控值处理
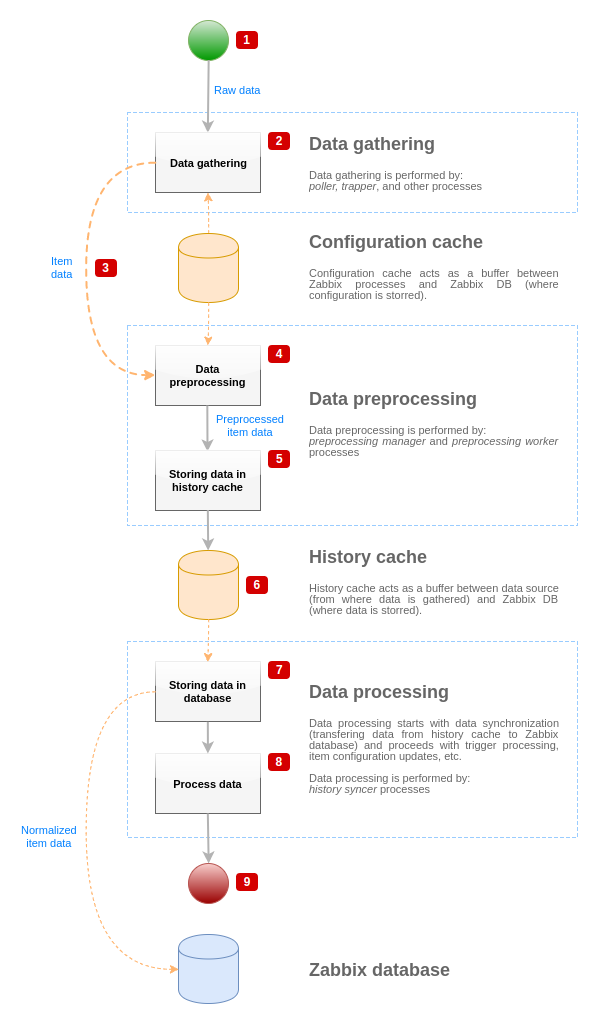
上面这个图示简单的描述了监控值处理过程中对应的步骤,包括进程、对象和动作等,并没有展示条件直接变化、错误处理。
- 开始于从源获取原始数据,这时数据只包含 ID,时间戳和值
- 不管使用何种类型的数据,对于主动和被动模式或 trapper 等方式都是一样。它只改变数据的格式,原始数据被验证,并从配置缓存里获取 item 配置
- 基于 socket 的 IPC 机制用来将数据从数据收集者传输给预处理管理进程。这时数据收集者不用等待预处理的响应,而是继续持续的去收集数据
- 数据预处理时包含预处理步骤的执行和依赖监控项的运行
- 预处理管理的本地缓存数据被刷新到历史缓存
- 这时数据流会暂停直到下一次历史缓存的刷新
- 同步进程开始于数据规范化存储在数据库中。数据规范化包括转换需要的格式,包括截取文本格式的数据为数据库表字段中可以支持的格式,在做完数据规范化后数据才会被发送到 database 中
- 收集的数据也被处理-检查触发器,如果数据不可用则会修改 item 的状态
Examples
主要介绍几种我在实际工作中常用的几种,其他的可以参考官方文档详细说明。
Text preprocessing
使用正则表达式获取数据,然后从文本格式传输最后存储为 number 格式。
这里使用正则表达式的时候包含两个参数:
- pattern-具体的表达式
- output-输出格式模板,\N(N = 1…9)转义会被替换成第 N 个匹配组,比如\0 则会被整个匹配文本所替代
比如一段日志文本里记录的温度 Temperature: 50C,作为监控需要提取其中的数字 50 作为最后的存储,于是这里则可以使用正则表达
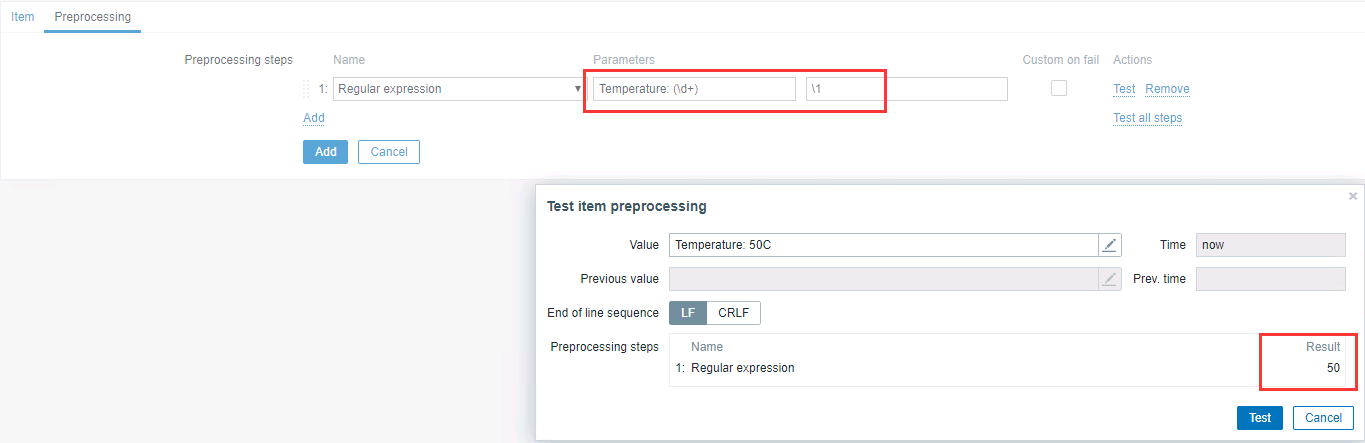
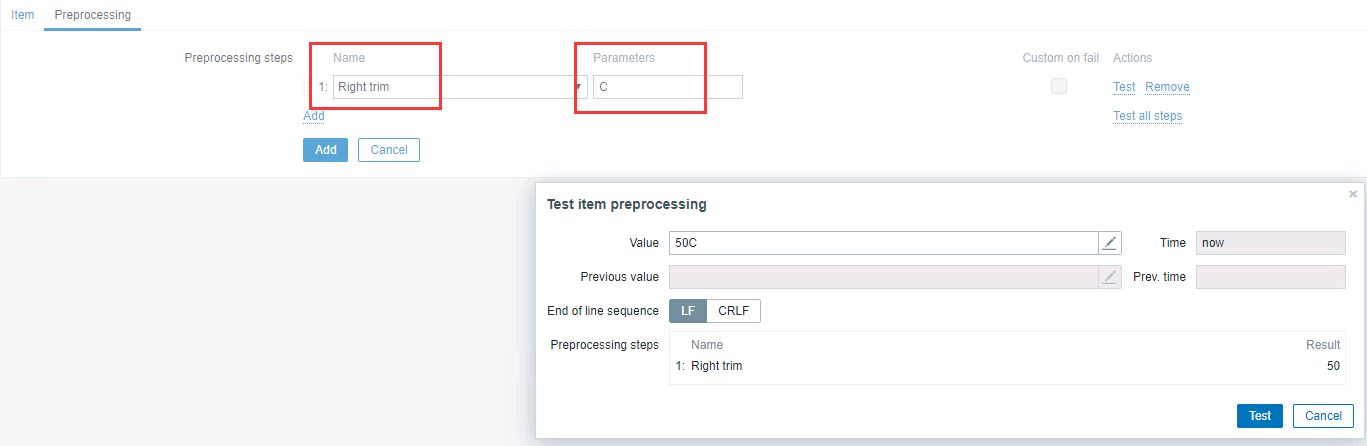
如果想将字符格式的值转换成数字型,可以通过 trim 来清除文本中的字符。
JSON 数据抽取
某个程序将进程所占用的资源情况全部记录在了日志当中,格式为
1 | {"proc":"TEST","cpu":3.6,"mem":5559784,"vir_mem":14303532,"net_in":2,"net_out":0} |
zabbix 通过监控得到了这个 json 串,但是对于数据的存放、数据的二次分析以及触发器的配置都是很不方便的,所以需要将 json 串的里每个值都拆开作为单独的多个监控,这里就可以用到 JSONPath 和 dependent item。
新建一个测试监控项,插入一条数据

新建 dependent item
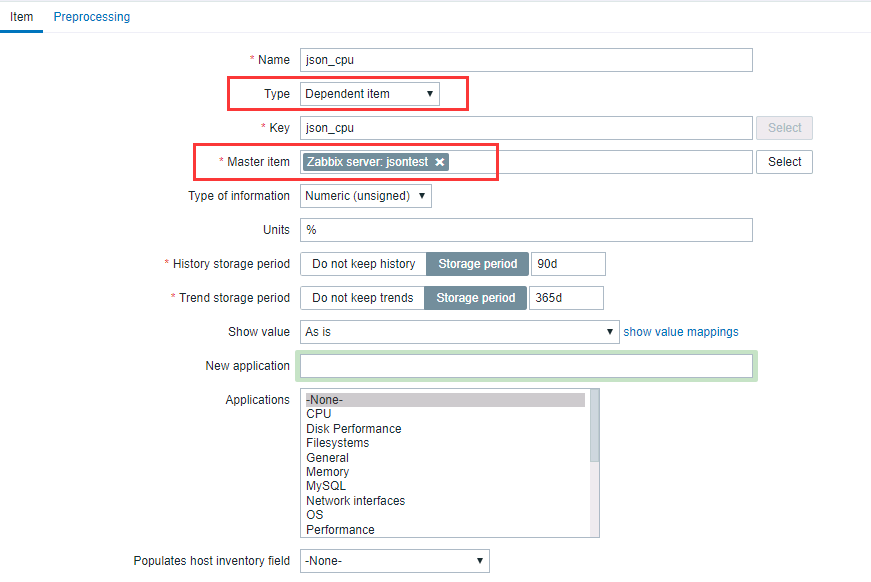
在 preprocessing tab 页,增加 JSONPath 处理
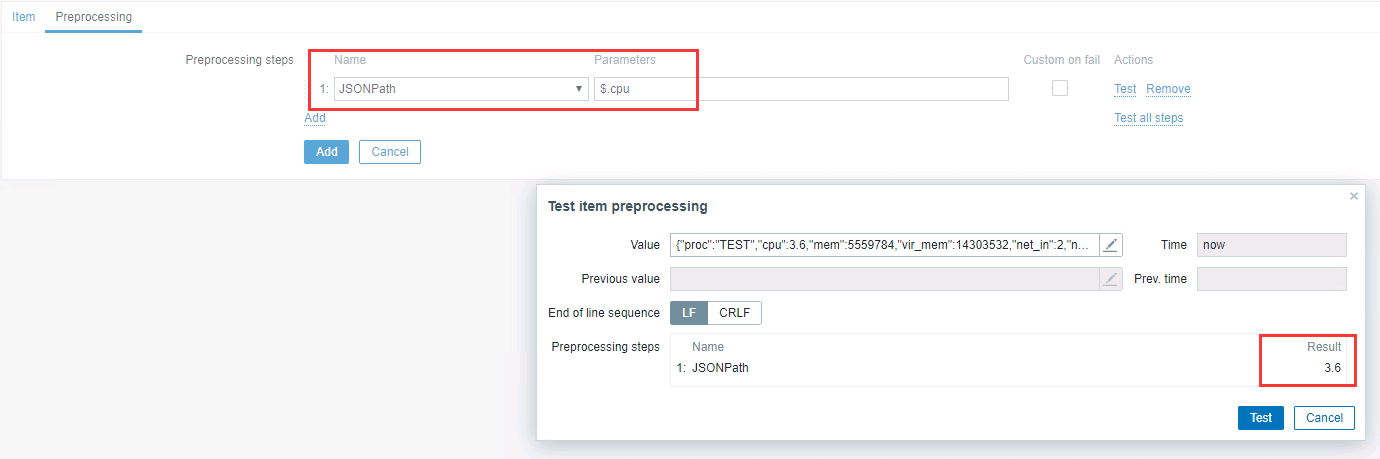
生成的结果

这样对于每次监控的 JSON 结果获取到以后,则会自动生成多个拆分出来的单项监控,便于后期处理。
jsonpath 的详细用法参考:https://www.zabbix.com/documentation/current/manual/appendix/preprocessing/jsonpath_functionality
自定义倍数
custom multipliers 很好理解,就是简单的乘以一个指定的倍数即可,常见的场景是在转换 bytes 到 bits,或者得到的内存单位是 KB,转换成 B 存储到 zabbix 里等。

throttling
这个功能主要是为了提高性能和节省数据库存储空间,特别是在一些高频的场景当中,对于那些监控得到的数据基本都是重复的情况下非常有用。
举个例子,当监控 zabbix agent 心跳网络时,我们需要比较高的频次,然后绝大部分情况下获取到的数据都是一模一样,通过 throttling,则可以将重复的数据都过滤掉,只存储监控值产生变化的情况。
throttling 也分为两种模式:
- 丢弃未变化——如果监控值没有变化则丢弃掉,这个数据也不会保存到数据库,zabbix server 也不知道获取到过这个值。触发器也不会生成相应的告警和恢复,因为触发器只会基于存储在数据库里的值起作用。trends 也是基于存储在数据库里的值建立,每个 item 只能有一个 throttling 选项
- 丢弃未变化(心跳模式)——在指定时间范围内丢弃没有变化的监控值,达到心跳时间时会仍然存储数据到数据库
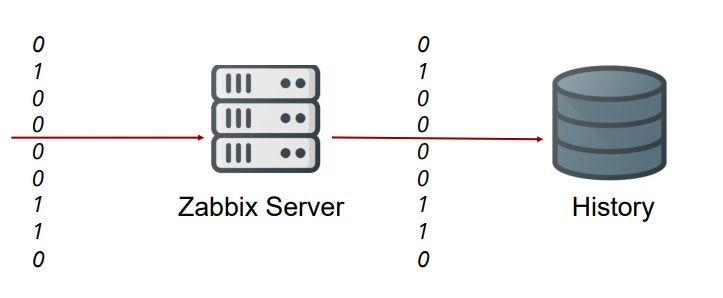
下面用图示来表达,监控项不断的进行采集,获取到的数据分布为 0 和 1
未使用 throttling 的情况:所有的数据都被存储到数据库里
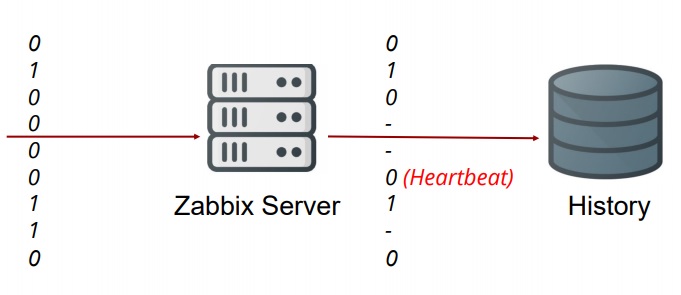
使用 throttling,重复的数据则被丢掉

增加心跳选项,可以避免 nodata 类型的触发器漏报
总结
通常有四大便利是你要考虑使用预处理的原因
- 自动化
- 通过主监控项进行 LLD
- 通过预处理发现指标
- 提升
- 丢弃重复数据
- 4.4 版本上直接在 proxy 层做预处理工作
- 自定义化
- 数据验证
- 自定义高级预处理规则
- 转换
- 转换数据
- 通过预处理进行数据合并和计算