zabbix告警优化
目前新zabbix系统添加了1300多台监控设备,3W多个触发器,每天的告警也是满天飞,造成了有用的信息通常淹没在了告警风暴当中。由于目前都采用的短信告警,成本上也是一笔不小的开支,所以就很必要对告警进行优化。
主要思路
告警依赖
有时候一台主机的可用性依赖于另一台主机。如果一台路由器宕机,则路由器后端的服务器将变得不可用。如果这两者都设置了触发器,你可能会收到关于两个主机宕机的通知,然而只有路由器是真正故障的。
这就是主机之间某些依赖关系可能有用的地方,设置依赖关系的通知可能会被抑制,而只发送根本问题的通知。
虽然Zabbix不支持主机之间的直接依赖关系,但是它们可以定义另外一种更加灵活的方式 - 触发器依赖关系。一个触发器可以有一个或多个依赖的触发器。
例如,主机位于路由器2后面,路由器2在路由器1后面。
Zabbix - 路由器1 - 路由器2 - 主机
如果路由器1宕机,显然主机和路由器2也不可达,然而我们不想收到主机、路由器1和路由器2都宕机的3条通知。
因此,在这种情况下我们定义了两个依赖关系:
‘主机宕机’ 触发器依赖于 ‘路由器2宕机’ 触发器
‘路由器2宕机’ 触发器依赖于 ‘路由器1宕机’ 触发器
在改变"主机宕机"触发器的状态之前,Zabbix将会检查相应触发器的依赖关系,如果找到,并且一个触发器处于"异常"状态,则触发器状态不会发生改变,因此不会执行动作,也不会发送通知。
Zabbix递归执行此检查,如果路由器1或路由器2是不可达的状态,那么主机触发器则不会更新。
所以根据zabbix提供的这个功能,对部分有依赖性的触发器之间做了关联,可以减少一部分告警。
告警升级
我给每个不同系统的群组分配了不同的权限,每个人收到的告警相对不会太多,但是作为领导或者权限更大的人来说,收到的告警数量数十倍增加,这个时候就需要对告警进行升级配置。
第一次出现告警的时候消息只发给一线运维人员,如果5分钟还没处理完才会发给级别或权限更大的人员。
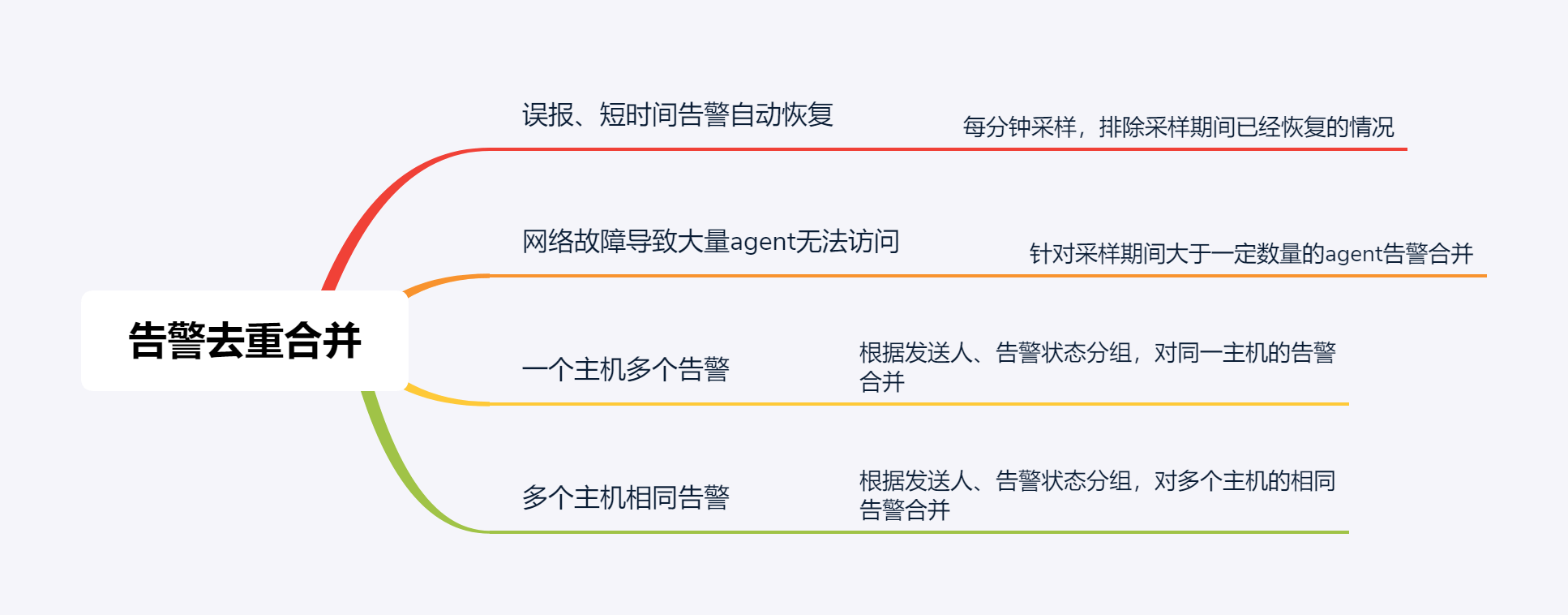
告警去重合并
我实际工作中碰过很多次因为网络抖动造成的大面积agent无法访问的告警,或者因为某些原因服务无法访问但是下一次监控周期即恢复正常的情况,这样会导致大量的误报。
针对于此,上面的两种办法都不能有效的应对这种场景,于是想到通过数据库的层面进行一些处理,主要思路是将生成的alert写库以后,再定期写入到一张临时表当中,对于告警发送周期范围内已经恢复正常的告警直接删除。对于agent大面积无法访问的误报进行告警合并。
对于动作的内容有点要求,这里用#符号作为分隔,方便数据库层面去处理字符串,只用配置subject即可
1 | #Operations: |
脚本
下载: https://github.com/xbdba/zabbix-alerts-optimize
通过create_table.sql创建相关表,resize_alerts.sql 为数据库存储过程,send_msg.py 调用存储过程,然后将最后的结果写入到短信库发出来。