oracle buffer cache
Granules
从10g开始引入了ASMM的功能,oracle会自动管理各个模块内存的使用,而granules则是oracle用于使用共享内存区域的最大内存单元。
在oracle的sga中,数据块都会读入到buffer cache这块内存区域当中,如果启用了ASSM,share pool中的部分区域会标记为KGH:NO ALLOC然后重新映射到buffer cache当中去,这是oracle会根据使用情况自动调整内存大小。
与数据缓存相关的主要有三部分:
最大的则是buffer阵列,主要用来存放从磁盘copy的数据块,其次为buffer header阵列,可以通过内存结构x$bh查看,其余则是少量的管理开销所需要的部分。
buffer header与buffer的联系非常紧密。buffer阵列的每一行与buffer header阵列中对应的每一行都有一个永久一对一的对应关系,buffer header与block header并不一样,buffer header包含一些关于block的信息,一些buffer状态的信息,和许多指向其他buffer header的指针。
Buffer池
每个granule都分配一个指定的buffer池,这表示任何一个granule都只包含同一个大小的buffer。
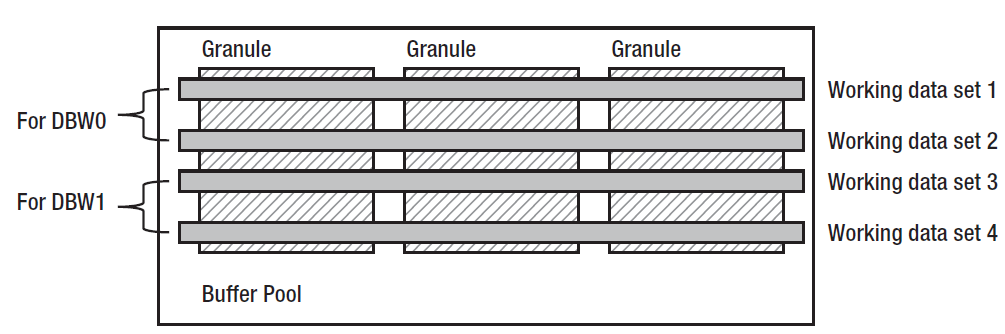
内存通常会被分成较小的一些块,这样会方便管理。将以块为单位的内存从一块区域(eg:data cache)移动到其他区域(eg:shared pool)是也会更容易。而管理这些块的机制最常见的就是LRU列表,但是这里要称之为工作数据集更加合适点。
每个不同的buffer池都可以分离出多个切片,主要为了减少需要当作一个整体进行维护的buffer数量。这些切片贯穿多个granule,所以如果一个buffer池由4个工作数据集(working data set)组成,每个切片则会包含granules当中1/4数量的buffer。每个buffer池都有相同数量的工作数据集,同时由于有8个buffer池,所以每个实例的工作数据集数量为8的倍数。
1 | PARAMETER_NAME TYPE VALUE |
工作数据集
工作数据集是一个非常重要的内存单元,是专门用来支持对buffer进行物理IO操作的部分。
1 | SQL> @desc x$kcbwds |
DBWR_NUM 每个工作数据集都有一个相关的dbwr进程,每个dbwr进程都会对应多个工作数据集。cnum_set表示数据集里含有的buffer数量,set_latch表示保护这个数据集的cache buffer lru chain的latch地址。剩下的几个字段其实就代表了replacement列表的地址,这里总共有两条列表,一个叫replacement列表(通常被称为LRU列表但不是完全精确),一个叫辅助replacement列表,从这里也可以看出都是双向列表,因为都是NXT和PRV成对出现。
我们知道一个工作数据集切片是覆盖多个granules,每个granule包含一组buffer headers,但是在x$kcbwds视图里可以看到一对链表的端点,如果检查x$bh可以看到另一对字段(nxt_repl和prv_repl)来知道链表是如何工作的。
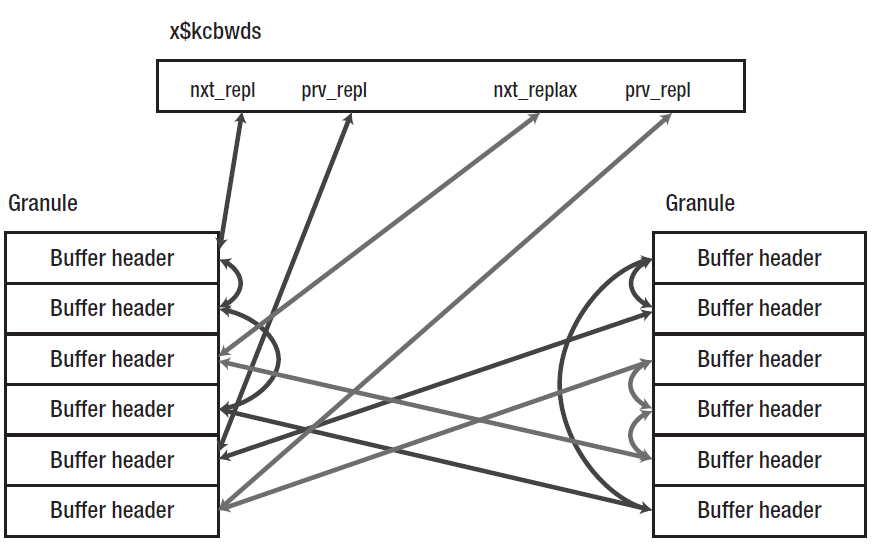
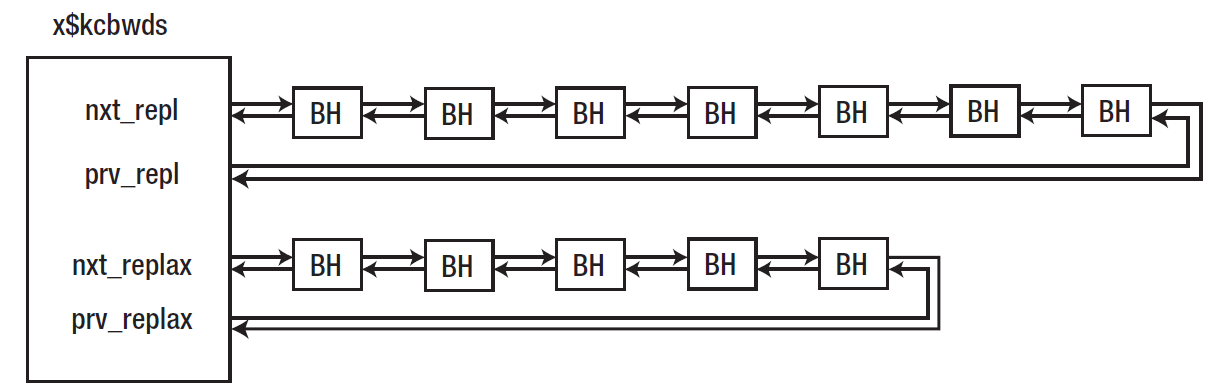
上图中上面的buffer header链也就是通常被称为LRU列表数据集,nxt_repl字段指向列表中最多访问的部分,而prv_repl字段则是指向列表中最少访问的部分。
这里cnum_repl是两条链表上所有pin住的buffer header数量总和,anum_repl则单独表示辅助replacement列表上pin住的buffer header数量。
LRU/TCH算法
lru算法解释参考https://en.wikipedia.org/wiki/Cache_replacement_policies
所有的buffer header都是通过一个双向链连接起来,每个buffer header都会指向一个buffer,每个buffer都会持有一个数据块的副本。现在要做的就是如果读取一个新数据块到内存,哪个buffer是可以被覆盖的。而oracle用到的算法并不是LRU算法,而是在LRU算法基础上修改后的TCH算法(touch count)
SQL> @desc x$bh
Name Null? Type
------------------------------- -------- ----------------------------
1 ADDR RAW(8)
2 INDX NUMBER
3 INST_ID NUMBER
4 CON_ID NUMBER
5 HLADDR RAW(8)
6 BLSIZ NUMBER
7 NXT_HASH RAW(8)
8 PRV_HASH RAW(8)
9 NXT_REPL RAW(8)
10 PRV_REPL RAW(8)
48 US_NXT RAW(8)
49 US_PRV RAW(8)
50 WA_NXT RAW(8)
51 WA_PRV RAW(8)
52 OQ_NXT RAW(8)
53 OQ_PRV RAW(8)
54 AQ_NXT RAW(8)
55 AQ_PRV RAW(8)
56 OBJ_FLAG NUMBER
57 TCH NUMBER
58 TIM NUMBER
通过x$bh结构可以看到包含了大量的PRV NXT字段对,也说明了buffer header包含了大量的指针,并且是双向的
传统的LRU算法在一个对象被访问后,则将其移动到列表的顶端,但是对于像buffer cache这样的部分来说,有大量的对象被同时使用,将这些对象一直移动则会造成大量的资源消耗并同时带来很多latch争用。为了解决这些问题,则引入了touch count的概念,改进了算法,增加了上面标红的字段,TCH计数器和时间标志TIM。每次buffer被访问时,都会更新tch和时间戳——需要从上次更新到现在超过3s。现在不会移动这个buffer header。
读取块到内存
x$bh视图里也有tch字段,x$kcbwds视图有一个中间点指针cold_hd。
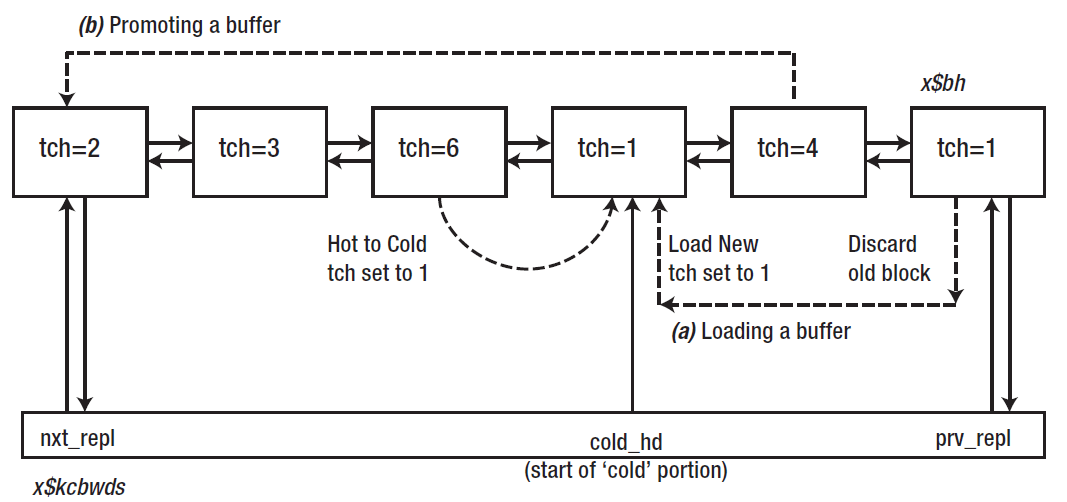
加载数据块到buffer
如果要读取一个全新的数据块到内存,首先需要找一个可用的buffer然后复制进去。这时要看哪些块可用,则从replacement列表的LRU端开始去查询。假设在列表的末端找到一个tch为1的buffer header,表示这个buffer从加载到内存到现在并没有被其他会话访问过,那么就是属于很少访问的冷块。还需要检查这个buffer是否正被pin住,并且其不需要被写回磁盘。假设所有的检查都通过,则会以排它模式pin住buffer header,读取数据块到buffer,更新buffer header里记录的相关信息,从列表的末端移除buffer header,并将其重链到列表的中点(v$kcbwds.cold_hd),然后unpin buffer header。
重链buffer
由于需要重新读取新块到内存,所以需要将buffer从原先的cache buffer chain上分离并且连接到新的上,也就表示需要同时获取两个cache buffer chain latch。
大致过程如下:
- 修改x$kcbwds.prv_repl指向列表中下一个buffer header
- 修改列表中下一个buffer header指回x$kcbwds
- 修改当前列表中点的两个buffer header指向我的buffer header而不是它们自己
- 修改x$kcbwds.cold_hd指向我的buffer header
- 将原先将buffer从原先的cache buffer chain上分离并且连接到新的上
- 将buffer与旧的对象分离并关联新的
假设tch=1的buffer已经加载了一个新的数据块,则它会被移动到中点,所以tch=4的buffer就变成了列表的最末端。对于不同的tch值的buffer来说,要读取一个新块到这个buffer时处理逻辑都有所不同。
buffer包含一个活跃块:
buffer自从加载数据块以后被访问了多次,所以不需要急着将其清出内存。oracle将buffer从列表的最LRU(最近最少使用)端分离并将其重新链接到MRU(最近最多使用)端,并将tch值减半,然后继续检查列表中下一个数据块。所以一个活跃块只有在快要被移出缓存的LRU端的情况下才会移动到MRU端,而并不是每次被使用时就会移动。
辅助LRU
当会话想搜寻buffer来读入数据块时,并不是优先从主replacement列表的LRU端去查询的,而是先搜索的辅助replacement列表的LRU端。辅助replacement列表主要存放的是那些几乎可以立即被使用的buffer header,由于这个原因,会使得在搜寻可用buffer的效率提高,它不需要消耗资源来考虑哪些是脏buffer、被pin住的buffer和其他需要考虑的问题。
寻找数据
因为buffer就是用来储存数据块的副本,所以内存里会包含大量的数据块,有些可能是重复的,同时dbwr进程也会定期将这些脏buffer写回磁盘。这时我们访问一个特定的数据块时,要如何知道是否应该重新从磁盘读取到内存,并且要如何快速有效的判断这个块已经不在内存了呢?
其实是采用hash表的方式,将一小段链接起来的buffer header附在每个bucket上,然后将这些bucket分成小组,通过一个cache buffer chains latch来保护这些小组,下面这个图表示了4个cache buffer chains latch,16个hash buckets,和23个buffer headers。
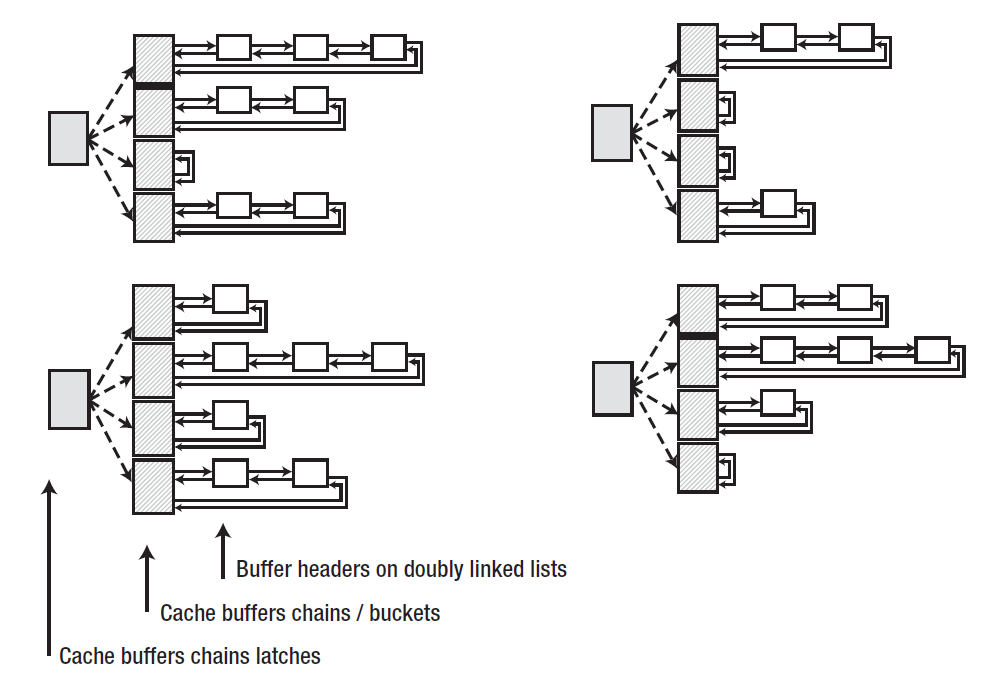
当我们有了一些buffer headers的集合后,可以通过定义合适的指针去链接相关的buffer headers来施加各种模式到这个集合上。cache buffer chains只是通过指针产生的其中一种模式,完全独立于granules,buffer pools,工作数据集,replacement列表等。
下面是需要访问一个buffer的大致过程
-
先将数据块的地址(DBAs:表空间、file_id、block_id的结合)进行hash算法计算,找到对应的hash bucket
-
获取保护这个hash bucket的cache buffer chains latch
-
如果获取latch成功,则读取buffer headers去查看指定版本的block是否已经在链表中,如果找到则直接访问buffer cache里的buffer,通过pin/unpin的动作来访问
如果没有找到block,则在buffer cache中找一个可用buffer,从当前链移出,重新链到新hash链上,释放latch然后读取数据块到这个可用buffer
-
如果获取latch失败,则一直spin到spin_count值的次数然后重新尝试获取latch,依旧失败则sleep然后继续尝试。