12.2统计信息之分区表
分区表上的统计信息要同时计算表级别和分区级别,11g以前新增一个分区或者修改少数分区的数据需要扫描整张表去刷新表的统计信息。如果跳过收集全局统计信息,那么优化器则会根据分区级别的统计信息去推断全局级别的统计信息。这种方法对于简单的表统计信息(例如行数)是准确的——通过聚合所有分区的行数,但是其他的统计信息就无法准确的推断。比如无法从每个分区独立的信息来准确推断出一个字段的唯一值记录(优化器使用的最重要统计信息之一)。
oracle 11g开始加强了这部分的统计信息收集手段,引入了增量全局统计信息。如果分区表的INCREMENTAL选项设置为true,DBMS_STATS.GATHER_*_STATS的GRANULARITY参数包含GLOBAL,并且ESTIMATE_PERCENT设置成AUTO_SAMPLE_SIZE,Oracle 会对新的分区收集信息,并且通过只扫描那些新增或进行修改了的分区从而准确的更新全局统计信息,这时就不需要扫描全表。
增量全局统计信息会对每个分区储存_概要_,_概要_表示分区和分区字段的元数据。每个概要都是储存在SYSAUX表空间。然后通过聚合每个分区级别的统计信息和分区概要来收集全局统计信息,因此就不需要扫描整张表来收集表级别统计信息。当一个新分区添加到表中,你只需要收集单个分区的统计信息,全局统计信息会自动维护和使用新分区的概要来准确更新数据。
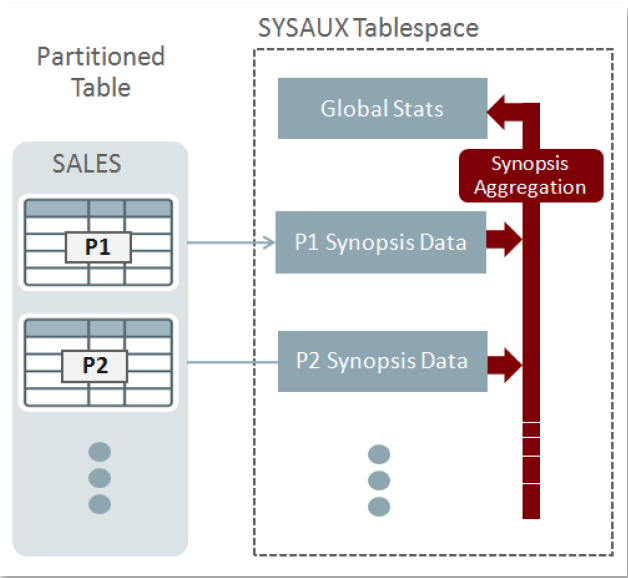
注意INCREMENTAL统计信息并不适用子分区,子分区和分区上的信息收集就跟正常的一样。只有分区上的统计信息用于更新全局或表级别的信息时,增量才有用。下面是如何使用增量统计信息
开启增量统计信息
1 | EXEC DBMS_STATS.SET_TABLE_PREFS('SH', 'SALES', 'INCREMENTAL', 'TRUE'); |
跟平常一样收集,ESTIMATE_PERCENT 和 GRANULARITY都是默认值
1 | exec DBMS_STATS.GATHER_TABLE_STATS('SH', 'SALES'); |
检查当前INCREMENTAL值
1 | SELECT DBMS_STATS.GET_PREFS('INCREMENTAL', 'SH', 'SALES') FROM dual; |
增量统计信息和过期
11g时,如果一个表上启用了增量统计信息,当一个分区的一行更新后,那么这个分区上的统计信息就被认为是过期的,如果要生成全局信息则必须要重新收集这个分区的统计信息。
12c有一个新的选项INCREMENTAL_STALENESS,能让你去控制什么时候分区统计信息被认为是过期的或者已经不适合用来生成全局统计信息了。默认这个值是NULL,表示分区有值变更时就立刻认为是过期(跟11g一样)。
它也可以设成USE_STALE_PERCENT或者USE_LOCKED_STATS,USE_STALE_PERCENT,表示变化的行数所占百分比小于设置的STALE_PRECENTAGE值时(默认10%),分区级别的统计信息一直被认为可用。USE_LOCKED_STATS表示如果一个分区的统计信息被锁定了,那么它就可以被用来生成全局统计信息而不用考虑这个分区从上次收集统计信息到现在有多少行记录做了变更。
给表ORDER_DEMO设置USE_STALE_PERCENT
1 | BEGIN |
修改默认的10%到20%
1 | BEGIN |
分区表统计信息锁定的情况
给表ORDER_DEMO设置USE_LOCKED_STATS
1 | BEGIN |
给表ORDER_DEMO同时设置USE_STALE_PERCENT和USE_LOCKED_STATS
1 | BEGIN |
增量统计和分区加载交换
分区的一个好处就是能快速而方便的加载数据,通过exchange partition命令能最小化对用户的影响。exchange partition命令可以让非分区表的数据交换到分区表中的指定分区。这个命令不是物理移动数据,而是更新数据字典交换指针从分区到表,反之亦然。
在之前的版本当中,是无法在分区交换的过程中对非分区表生成必要的统计信息用于支持增量统计信息。而是必须在分区交换动作完成以后才能收集,为了确保全家统计信息能被增量维护。
在12c中,必要的统计信息(概要)可以在交换之前就创建在非分区表上,所以在分区交换的过程中统计信息也被交换用于自动维护增量的全家统计信息。新的DBMS_STATS表选项INCREMENTAL_LEVEL可以被用来去确定一个将要做加载交换的非分区表。INCREMENTAL_LEVEL设成TABLE时(默认PARTITION),oracle将在收集统计信息时自动为表创建概要。这个表级别的概要将在分区交换完毕后变成分区的概要。
1 | exec dbms_stats.set_table_prefs ('SH','EXCHANGETAB','INCREMENTAL','TRUE'); |
概要增强
对于那些含有大量分区表的数据仓库应用来说,增量维护节省了大量的时间。然而带来了性能上的收益却也伴随这磁盘费用的增加:概要信息都是储存在SYSAUX表空间,需要越来越多的磁盘用来存储那些超多分区、超多字段、特别是那些字段唯一性特别高的表的概要。除了磁盘的消耗,你必须也要考虑到维护大量概要信息所带来的资源消耗。
从12.2开始,DBMS_STATS包提供了对于收集唯一值信息的新算法,在精确度与以前相似的条件下产生少的多的概要。
DBMS_STATS的新选项APPROXIMATE_NDV_ALGORITHM用来控制创建哪种概要。默认值是REPEAT OR HYPERLOGLOG,表示那些已存在的自适应采用算法将适用于已存在的概要,但是新概要都通过新的HYPERLOGLOG算法。在同一张表中可以混合新旧算法同时使用。
当将一个12.2之前的版本升级到12.2(使用增量信息)时,有三个选项:
1.继续使用12.2以前的格式
调整DBMS_STATS参数为adaptive sampling
1 | EXEC dbms_stats.set_database_prefs ('approximate_ndv_algorithm', 'adaptive sampling'); |
2.立刻调整旧算法为新的
所有分区的统计信息会被重新收集
1 | EXEC dbms_stats.set_database_prefs ('approximate_ndv_algorithm', 'hyperloglog'); |
3.逐渐用新算法替换旧算法
旧的概要不会被立即删掉,新的分区会采用新算法格式的概要。混合模式可能会产生不太准确的统计信息,但是这样就不需要在前台重新收集所有统计信息,因为自动统计信息收集任务将重新收集具有旧概要的分区信息,并使用新格式。到最后所有的概要都会处于新的格式,统计信息也都会精确。
1 | EXEC dbms_stats.set_database_prefs ('approximate_ndv_algorithm', 'hyperloglog'); |