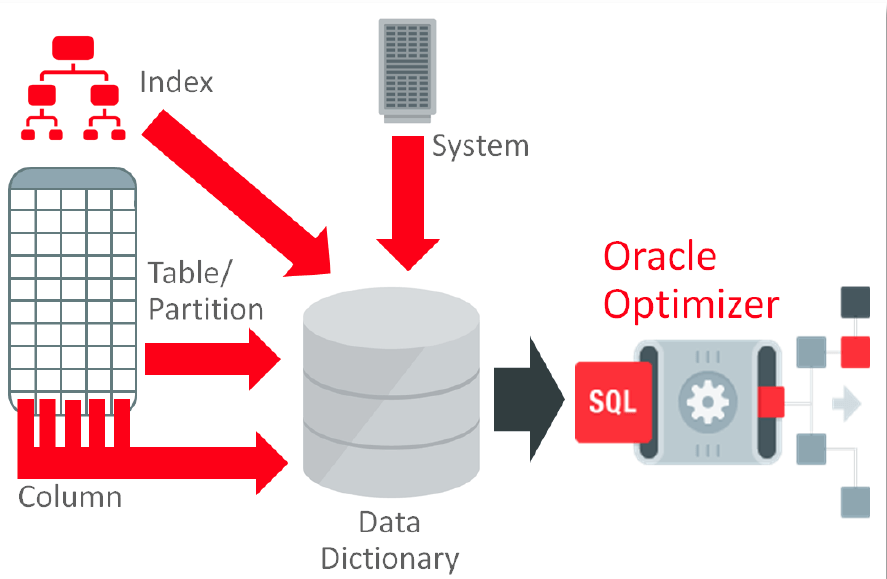
介绍 很早之前的版本中,如何执行一个sql语句是由RBO(Rule Based Optimizer)决定的,根据一些设定好的规则来生成执行计划。
后来的版本中CBO(Cost Based Optimizer)被引入进来。CBO检查sql所有可能的执行计划然后选择其中cost最低的一个,cost其实就是反应了执行计划估算的资源消耗。cost越低,这个执行计划也就被认为效率越高。为了能让CBO计算出更准确的cost值,就必须要有sql所有的访问对象的相关信息,包括表、索引等。
这些必要的信息统称为统计信息,理解和管理统计信息对于获得一个好的执行计划是非常重要的。
什么是统计信息 统计信息是用来描述数据库和它其中的对象的数据,这些信息能被优化器使用用于对每个sql生成最好的执行计划。统计信息储存在数据字典当中,能直接通过字典视图来访问,例如USER_TAB_STATISTICS
大部分的统计信息需要定期收集和更新,用来确保当前的信息能真实反映实际储存在数据库中的数据情况。举个例子:部分交易表非常活跃,经常有大量数据的操作,那么这些表就需要经常更新统计信息。而另外一些历史归档表由于历史数据并没有被经常使用,只是时而被查询,那么这些表就不需要定期更新。所以是否需要收集统计信息完全是根据需要来的。
表和列的统计信息 表的统计信息包含有多少行数据,使用了多少个数据块,平均每一行数据使用了多少个byte等等。优化器使用这些信息并且结合其他的一些相关信息,计算出不同执行计划所需的cost,并且估算出各个操作所返回的记录数。比如访问某张表的cost则是用表的数据块数结合参数DB_FILE_MULTIBLOCK_READ_COUNT计算得出。你可以直接通过视图USER_TAB_STATISTICS来查询。
列的统计信息则包括列的唯一值数量(NDV),和列的最大值与最小值,可以通过USER_TAB_COL_STATISTICS视图查询。优化器通过这些信息结合表的相关信息来估算出sql每一步操作会返回的记录数。如果一张表有100行,查询的列上有10个唯一值,那么优化器估算的返回值也为100/10=10。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 drop table t purge; create table t as select mod(level,10) id from dual connect by level>=100; sys@ORA12C> @grp id t count id in table t... ID COUNT(*) ---------- ---------- 0 10 1 10 2 10 3 10 4 10 5 10 6 10 7 10 8 10 9 10 sys@ORA12C> select count(1) from t where id=1; Execution Plan ---------------------------------------------------------- Plan hash value: 2966233522 --------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 13 | 2 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | 13 | | | |* 2 | TABLE ACCESS FULL| T | 10 | 130 | 2 (0)| 00:00:01 | >>>>==== ROWs估算为10 --------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - filter("ID"=1) Note ----- - dynamic statistics used: dynamic sampling (level=2) Statistics ---------------------------------------------------------- 6 recursive calls 5 db block gets 19 consistent gets 0 physical reads 0 redo size 542 bytes sent via SQL*Net to client 607 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed
额外列统计信息 表和列的统计信息给了优化器很多信息,但是其无法提供一个机制来告诉优化器表或列当中数据的性质。比如这些统计信息无法提供列的数据是否分布均匀,或者多个列的数据是否有关联关系。这种类型的信息只能通过扩展统计信息来获得。其中包括直方图,组合列和表达式统计信息。如果没有这些,那么优化器会默认数据是分布均匀的,然后所有列之间的数据并无关联关系。
直方图 直方图给优化器提供了列数据的分布情况,根据之前的例子,优化器是默认用总行数/唯一值来估算返回记录,如果列的数据分布不均匀,那么得到的结果就区别很大。为了准确反映一个不均匀的数据分布,就需要对列收集直方图。
oracle会自动决定列是否要收集直方图,取决于列的使用情况(SYS.COL_USAGE$),和数据倾斜的状况。比如当一个唯一列总是以等式出现在谓词条件中时,oracle不会对其自动创建直方图。
目前总共有4种直方图:frequency, top-frequency, height-balanced 和 hybrid(top-frequency和hybrid是12c新引入),oracle自动选择合适的类型。一般取决于列上的唯一值数量,可以通过user_tab_col_statistics视图的histogram字段来查询每一列的直方图类型。
frequency Histograms 当列的唯一值小于最大的桶的数量阀值时,默认创建frequency直方图。桶的最大值默认是254,但是可以通过DBMS_STATS来修改成最高至2048(从12c开始)
将之前的数据做下处理,然后收集直方图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 delete from t where id=1 and rownum >=9; delete from t where id=2 and rownum >=8; delete from t where id=3 and rownum >=7; delete from t where id=4 and rownum >=6; delete from t where id=5 and rownum >=5; delete from t where id=6 and rownum >=4; delete from t where id=7 and rownum >=3; delete from t where id=8 and rownum >=2; delete from t where id=9 and rownum >=1; commit; sys@ORA12C> @grp id t count id in table t... ID COUNT(*) ---------- ---------- 0 10 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 exec dbms_stats.gather_table_stats(USER,'T',method_opt=>'for all columns size auto');
现在来看一下直方图的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 select endpoint_value,endpoint_number,endpoint_number-lag(endpoint_number,1,0) over(order by endpoint_number) as frequency from user_tab_histograms where table_name='T' and column_name='ID' order by 2; ENDPOINT_VALUE ENDPOINT_NUMBER FREQUENCY -------------- --------------- ---------- 0 10 10 1 11 1 2 13 2 3 16 3 4 20 4 5 25 5 6 31 6 7 38 7 8 46 8 9 55 9
FREQUENCY表示每一个桶值,也就是这个值有多少条记录数。oracle频度直方图将桶称为”endpoint values”,上面的结果就是表示有0-9总共10个桶,ENDPOINT_NUMBER这代表着累计频度,比如endpoint values为1的累计频度就是前后的FREQUENCY的累加值,10+1=11。
注意到ENDPOINT_VALUE为number型,所以对于非number类型的字段收集直方图以后,存储在ENDPOINT_VALUE字段的值也会转码成number型。
1 2 3 4 5 6 7 8 9 10 11 sys@ORA12C> @desc user_tab_histograms Name Null? Type ------------------------------- -------- ---------------------------- 1 TABLE_NAME VARCHAR2(128) 2 COLUMN_NAME VARCHAR2(4000) 3 ENDPOINT_NUMBER NUMBER 4 ENDPOINT_VALUE NUMBER >>>>====这里是number类型 5 ENDPOINT_ACTUAL_VALUE VARCHAR2(4000) 6 ENDPOINT_ACTUAL_VALUE_RAW RAW(2000) 7 ENDPOINT_REPEAT_COUNT NUMBER 8 SCOPE VARCHAR2(7)
当直方图创建完毕以后,优化器就能估算的更加准确。比如id=1时,优化器立刻能知道记录只有1条,就会走索引之类。
高度平衡直方图 与频度直方图相反的是,当列的唯一值大于最大的桶的数量阀值时,默认创建高度平衡直方图。桶的最大值默认是254,但是可以通过DBMS_STATS来修改成最高至2048(从12c开始)。
频度直方图在面对字段有大量唯一值时就比较乏力,因为它每个桶中只存放了一个值,所以随着直方图数量的不断增加,系统在存储、使用和维护这些直方图时就会需要大量的资源。12c开始,在多数情况下oracle采用了新的混合直方图来取代高度平衡直方图,稍后会介绍到混合直方图。
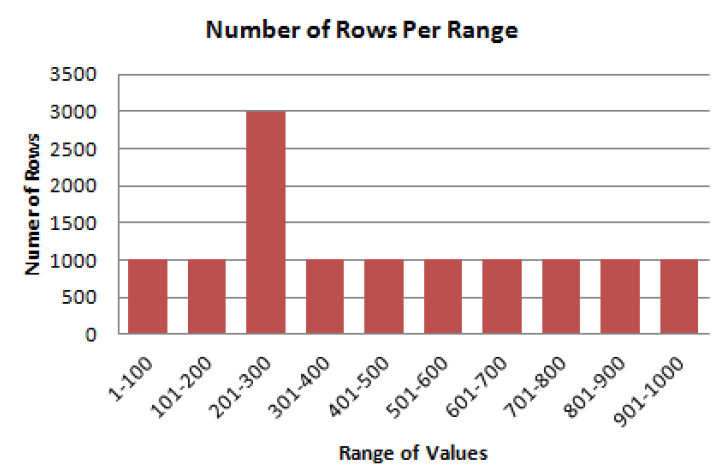
假设一个表含有字段COL1,值从1到1000,下图展示出将数据切分成数个范围。值从1到100的记录数有1000行,值从201到300直接的值突然增高到3000
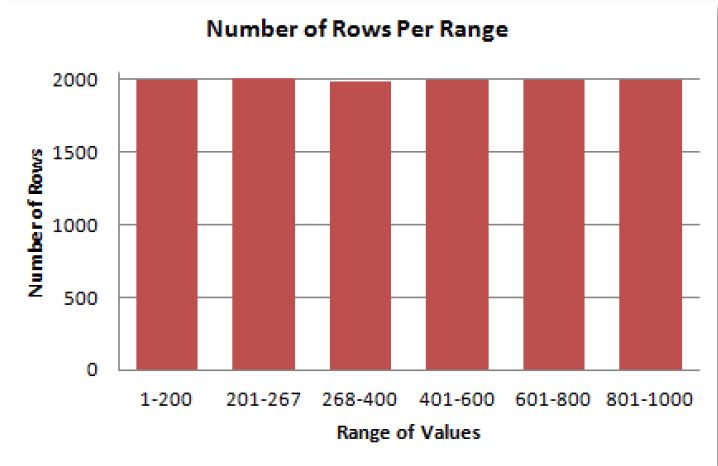
如果将同样的数据换成高度平衡直方图的话,通过平衡每个范围的大小,可以将每个范围的值调整成近似相等。换句话说,每个垂直条都有近似的高度。比如值1-200有2000行,下一个范围201-267也保持在2000行左右,因为201-300范围的值比较多。
Top-Frequency直方图 传统而言当列的唯一值大于最大的桶的数量阀值时,就会创建高度平衡直方图或者混合直方图。然而有些情况下列中大多数数据都是重复的,其余的相对少量数据却含有大量的唯一值,也就是说数据分布极不均匀。在这种情况下,更适合对表的大多数记录创建频度直方图,忽略对统计信息不重要的一组记录(基数小但是唯一值多)。当选择频度直方图时,数据库必须决定最大的桶数阀值是否足够去准确的计算基数,即使行中的唯一值数量已经超过了这个阀值。它计算列中99.6%的行中有多少个不同的值(99.6%是默认值,但是这个值会根据直方图的数量进行调整)。如果有足够的直方图桶可以用来容纳前N个不同的值,那么将为这些活跃的值创建频率直方图。
在收集统计信息时,只有参数ESTIMATE_PERCENT被设成AUTO_SAMPLE_SIZE(默认值)时,才会创建Top-Frequency直方图,因为必须查看列中的所有值,才能判断是否满足必要的条件(行中的99.6%有254或者更少的唯一值)。
构建一张表包含10000条数据,其中9000条随机1-9,大致上每个值含有1000条数据,其余的值都是唯一值。故总的唯一值数为1009,远超254的阀值。参数METHOD_OPT限制每个桶不超过10
1 2 3 4 5 6 7 8 9 10 11 DROP TABLE t1 PURGE; CREATE TABLE t1 AS SELECT CASE WHEN level >= 9000 THEN TRUNC(DBMS_RANDOM.value(1,10)) ELSE level END AS id FROM dual CONNECT BY level >= 10000; EXEC DBMS_STATS.gather_table_stats(USER, 't1', method_opt => 'FOR COLUMNS ID SIZE 10');
通过USER_TAB_COLUMNS视图可以查到直方图类型
1 2 3 4 5 6 7 8 9 SELECT column_id, column_name, histogram FROM user_tab_columns WHERE table_name = 'T1'; COLUMN_ID COLUMN_NAME HISTOGRAM ---------- -------------------- --------------------------------------------- 1 ID TOP-FREQUENCY
下面这个查询展示了Top-Frequency直方图中每个值以及其结束点值和频度,注意到重复度高的值展示的是一个正常的频度直方图,而重复度低的值则被分组成一个低频度的组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 select endpoint_value,endpoint_number, endpoint_number-lag(endpoint_number,1,0) over(order by endpoint_number) as frequency from user_tab_histograms where table_name='T1' and column_name='ID' order by 2; ENDPOINT_VALUE ENDPOINT_NUMBER FREQUENCY -------------- --------------- ---------- 1 995 995 2 1981 986 3 2971 990 4 3950 979 5 4960 1010 6 5950 990 7 6932 982 8 7952 1020 9 9000 1048 10000 9001 1
混合直方图 混合直方图类似频度和高度平衡直方图的一个结合,大多数情况下,12c采用混合直方图来取代传统的高度直方图。跟高度平衡直方图不一样的是,混合直方图中结束点值不能跨越桶,除了桶中的最高值外,混合直方图还储存最高值的次数,从而准确的了解其活跃程度,同时也能了解其他结束点值的活跃程度。那么混合直方图如何表示一个活跃的值呢?记录每个结束点值的频率(记录在新字段endpoint_repeat_count),从而提供每个结束点值的活跃程度。
下面这张表有10000行,有5000行随机1-99,其余5000行值唯一。
1 2 3 4 5 6 7 8 9 DROP TABLE t1 PURGE; CREATE TABLE t1 AS SELECT CASE WHEN MOD(level,2) = 0 THEN TRUNC(DBMS_RANDOM.value(1,100)) ELSE level END AS id FROM dual CONNECT BY level >= 10000;
这里为了触发在正常收集统计信息的时候收集直方图,先用重复度的高的条件查询一遍做硬解析。
1 2 3 4 5 6 7 8 9 sys@ORA12C> select count(1) from t1 where id=1; COUNT(1) ---------- 48 sys@ORA12C> EXEC DBMS_STATS.gather_table_stats(USER, 't1'); PL/SQL procedure successfully completed.
通过USER_TAB_COLUMNS视图可以查到直方图类型
1 2 3 4 5 6 7 8 9 SELECT column_id, column_name, histogram FROM user_tab_columns WHERE table_name = 'T1'; COLUMN_ID COLUMN_NAME HISTOGRAM ---------- -------------------- --------------------------------------------- 1 ID HYBRID
下面的结果可以看到混合直方图同时具有频度和高度平衡直方图的特性,桶可以包含多个值,终点值存储累计频度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 select histogram,num_buckets from user_tab_col_statistics where table_name='T1' and column_name='ID'; HISTOGRAM NUM_BUCKETS --------------------------------------------- ----------- HYBRID 254 select endpoint_value,endpoint_number,endpoint_repeat_count, endpoint_number-lag(endpoint_number,1,0) over(order by endpoint_number) as frequency from user_tab_histograms where table_name='T1' and column_name='ID' order by 2; ENDPOINT_VALUE ENDPOINT_NUMBER ENDPOINT_REPEAT_COUNT FREQUENCY -------------- --------------- --------------------- ---------- 1 48 48 48 2 92 44 44 3 146 54 54 4 195 49 49 5 245 50 50 6 301 56 56 7 351 50 50 8 397 46 46 9 440 43 43 10 478 38 38 11 517 39 39 12 565 48 48 13 602 37 37 14 649 47 47 15 704 55 55 16 744 40 40 17 799 55 55 18 856 57 57 19 912 56 56 20 962 50 50 21 1008 46 46 22 1068 60 60 23 1127 59 59 24 1185 58 58 25 1231 46 46 26 1282 51 51 27 1333 51 51 28 1385 52 52 29 1434 49 49 30 1481 47 47 31 1530 49 49 32 1579 49 49 33 1630 51 51 34 1681 51 51 35 1736 55 55 36 1799 63 63 37 1852 53 53 38 1908 56 56 39 1966 58 58 40 2009 43 43 41 2061 52 52 42 2109 48 48 43 2158 49 49 44 2213 55 55 45 2253 40 40 46 2307 54 54 47 2362 55 55 48 2415 53 53 49 2460 45 45 50 2516 56 56 51 2557 41 41 52 2618 61 61 53 2665 47 47 54 2733 68 68 55 2787 54 54 56 2838 51 51 57 2895 57 57 58 2951 56 56 59 3023 72 72 60 3068 45 45 61 3123 55 55 62 3179 56 56 63 3235 56 56 64 3272 37 37 65 3342 70 70 66 3392 50 50 67 3439 47 47 68 3498 59 59 69 3557 59 59 70 3596 39 39 71 3645 49 49 72 3695 50 50 73 3745 50 50 74 3782 37 37 75 3842 60 60 76 3891 49 49 77 3948 57 57 78 3989 41 41 79 4048 59 59 80 4095 47 47 81 4153 58 58 82 4198 45 45 83 4250 52 52 84 4308 58 58 85 4346 38 38 86 4395 49 49 87 4448 53 53 88 4505 57 57 89 4554 49 49 90 4604 50 50 91 4644 40 40 92 4689 45 45 93 4743 54 54 94 4797 54 54 95 4851 54 54 96 4894 43 43 97 4953 59 59 98 5003 50 50 99 5050 47 47 163 5082 1 32 227 5114 1 32 291 5146 1 32 355 5178 1 32 419 5210 1 32 483 5242 1 32 547 5274 1 32 611 5306 1 32 677 5339 1 33 741 5371 1 32 805 5403 1 32 869 5435 1 32 933 5467 1 32 997 5499 1 32 1061 5531 1 32 1125 5563 1 32 1189 5595 1 32 1253 5627 1 32 1317 5659 1 32 1383 5692 1 33 1447 5724 1 32 1511 5756 1 32 1575 5788 1 32 1639 5820 1 32 1703 5852 1 32 1767 5884 1 32 1831 5916 1 32 1895 5948 1 32 1959 5980 1 32 2025 6013 1 33 2089 6045 1 32 2153 6077 1 32 2217 6109 1 32 2281 6141 1 32 2345 6173 1 32 2409 6205 1 32 2473 6237 1 32 2537 6269 1 32 2601 6301 1 32 2665 6333 1 32 2731 6366 1 33 2795 6398 1 32 2859 6430 1 32 2923 6462 1 32 2987 6494 1 32 3051 6526 1 32 3115 6558 1 32 3179 6590 1 32 3243 6622 1 32 3307 6654 1 32 3371 6686 1 32 3437 6719 1 33 3501 6751 1 32 3565 6783 1 32 3629 6815 1 32 3693 6847 1 32 3757 6879 1 32 3821 6911 1 32 3885 6943 1 32 3949 6975 1 32 4013 7007 1 32 4077 7039 1 32 4143 7072 1 33 4207 7104 1 32 4271 7136 1 32 4335 7168 1 32 4399 7200 1 32 4463 7232 1 32 4527 7264 1 32 4591 7296 1 32 4655 7328 1 32 4719 7360 1 32 4785 7393 1 33 4849 7425 1 32 4913 7457 1 32 4977 7489 1 32 5041 7521 1 32 5105 7553 1 32 5169 7585 1 32 5233 7617 1 32 5297 7649 1 32 5361 7681 1 32 5425 7713 1 32 5491 7746 1 33 5555 7778 1 32 5619 7810 1 32 5683 7842 1 32 5747 7874 1 32 5811 7906 1 32 5875 7938 1 32 5939 7970 1 32 6003 8002 1 32 6067 8034 1 32 6131 8066 1 32 6197 8099 1 33 6261 8131 1 32 6325 8163 1 32 6389 8195 1 32 6453 8227 1 32 6517 8259 1 32 6581 8291 1 32 6645 8323 1 32 6709 8355 1 32 6773 8387 1 32 6839 8420 1 33 6903 8452 1 32 6967 8484 1 32 7031 8516 1 32 7095 8548 1 32 7159 8580 1 32 7223 8612 1 32 7287 8644 1 32 7351 8676 1 32 7415 8708 1 32 7479 8740 1 32 7545 8773 1 33 7609 8805 1 32 7673 8837 1 32 7737 8869 1 32 7801 8901 1 32 7865 8933 1 32 7929 8965 1 32 7993 8997 1 32 8057 9029 1 32 8121 9061 1 32 8185 9093 1 32 8251 9126 1 33 8315 9158 1 32 8379 9190 1 32 8443 9222 1 32 8507 9254 1 32 8571 9286 1 32 8635 9318 1 32 8699 9350 1 32 8763 9382 1 32 8827 9414 1 32 8891 9446 1 32 8957 9479 1 33 9021 9511 1 32 9085 9543 1 32 9149 9575 1 32 9213 9607 1 32 9277 9639 1 32 9341 9671 1 32 9405 9703 1 32 9469 9735 1 32 9533 9767 1 32 9599 9800 1 33 9663 9832 1 32 9727 9864 1 32 9791 9896 1 32 9855 9928 1 32 9919 9960 1 32 9983 9992 1 32 9999 10000 1 8